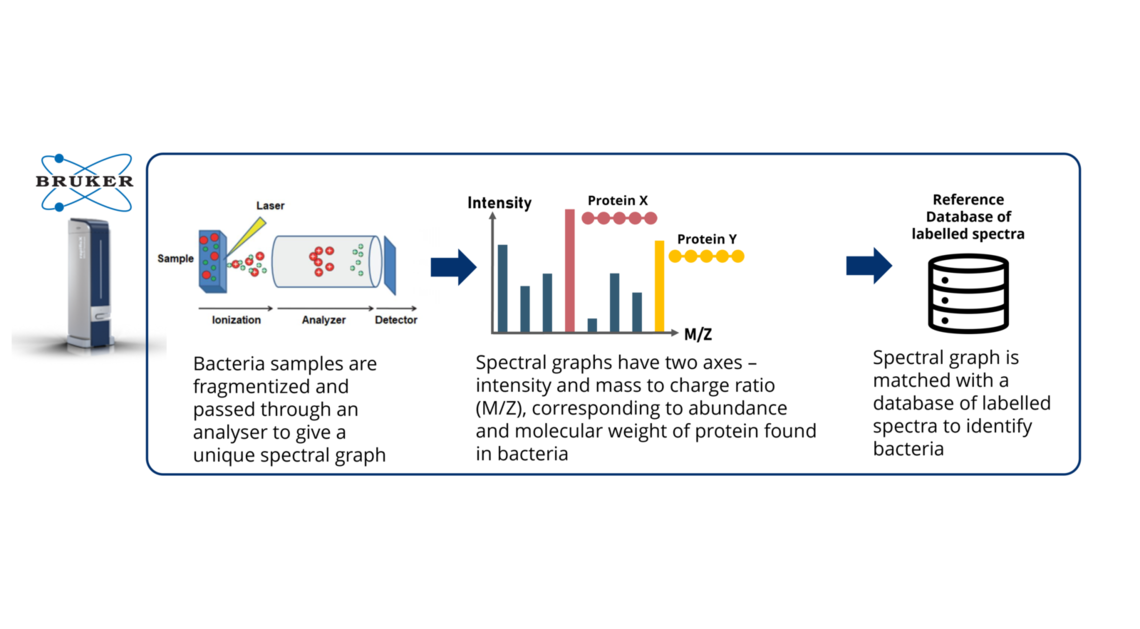
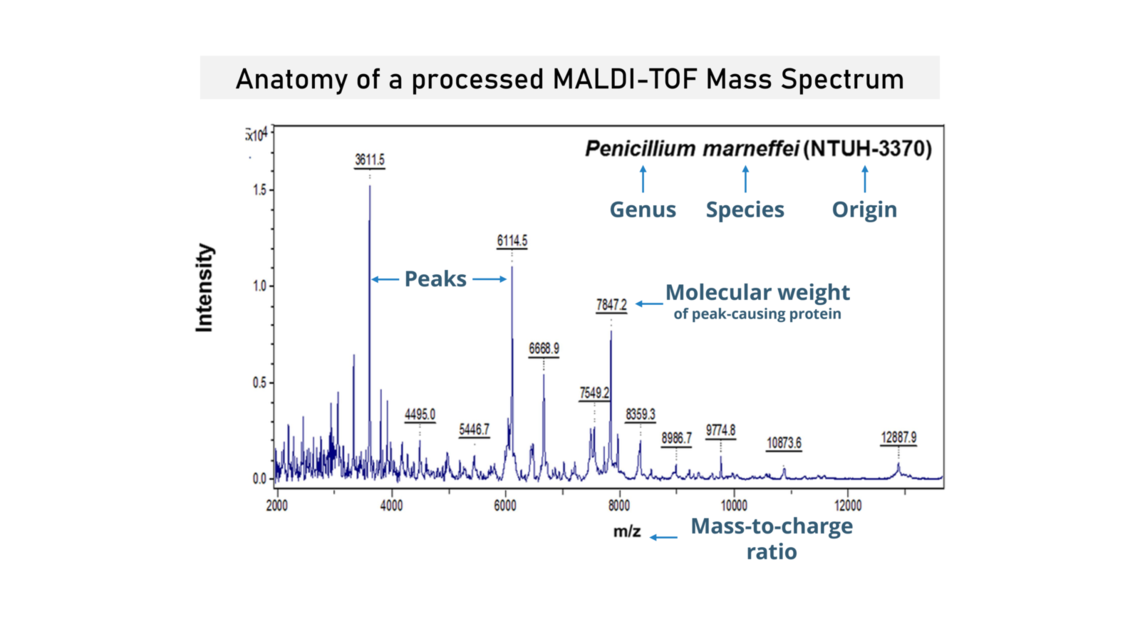
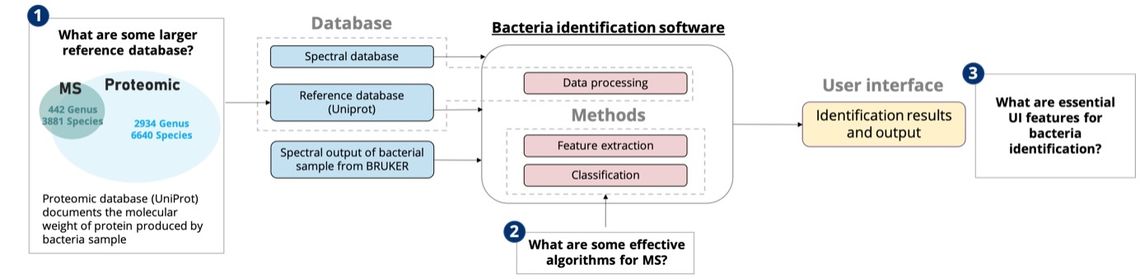
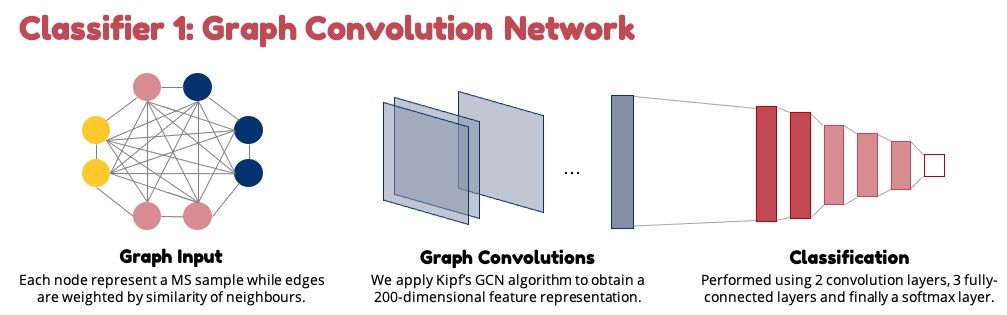
CAPSTONE DESIGN SHOWCASE 2021
-
DAYS
-
HOURS
-
MINUTES
-
SECONDS
COMING SOON


Team members
Ku Wee Tiong (ESD), Choo Yan Guang (ESD), Lee En Qi Amanda (ESD), Chan Luo Qi (ISTD), Seow Xu Liang (ISTD), Zhang Jingyu (ISTD)
Instructors:
Kenny Choo, Wang Xingyin, Lynette Cheah
Writing Instructors:
Teaching Assistant:
 Ku Wee Tiong
Engineering Systems and Design
Ku Wee Tiong
Engineering Systems and Design
 Choo Yan Guang
Engineering Systems and Design
Choo Yan Guang
Engineering Systems and Design
 Lee En Qi Amanda
Engineering Systems and Design
Lee En Qi Amanda
Engineering Systems and Design
 Chan Luo Qi
Information Systems Technology and Design
Chan Luo Qi
Information Systems Technology and Design
 Seow Xu Liang
Information Systems Technology and Design
Seow Xu Liang
Information Systems Technology and Design
 Zhang Jingyu
Information Systems Technology and Design
Zhang Jingyu
Information Systems Technology and Design
Ku Wee Tiong
Engineering Systems and Design
Choo Yan Guang
Engineering Systems and Design
Lee En Qi Amanda
Engineering Systems and Design
Chan Luo Qi
Information Systems Technology and Design
Seow Xu Liang
Information Systems Technology and Design
Zhang Jingyu
Information Systems Technology and Design